





# Ref
https://wlsdn3004.tistory.com/50
Grafana Mimir란? 개념부터 설치까지
Prometheus는 쿠버네티스 환경에서 많이 사용하는 인기 있는 오픈소스 모니터링 도구이다. 하지만 몇 가지 치명적인 단점이 있다. 확장 및 고가용성 문제 프로메테우스는 단일 서버로 동작하게 구
wlsdn3004.tistory.com
Mimir가 뭔지와 컴포넌트에 대한 자세한 설명은 위를 확인하자.
나는 Mimir를 설치하고, Prometheus 연동 중 트슛 과정만 설명한다.
# 권한 설정 먼저
일단 mimir의 데이터는 s3에 담을 것이다.
iam policy는 아래처럼 구성하면 된다.
{
"Statement": [
{
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::${S3_BUCKET_NAME}",
"arn:aws:s3:::${S3_BUCKET_NAME}/*",
]
"Sid": "objects"
}
],
"Version": "2012-10-17"
}
IRSA를 위한 IAM Role을 만드는 방법에 대해선 생략하겠다.
# Mimir Helm Install - 우선 띄우기만
나는 mimir-distributed chart의 5.3.0-weekly.281 버전을 사용했다.
아래 values file로 mimir를 띄우는 것에 성공했다.
(storage backend - s3 설정 & nginx를 별도로 띄우는 대신 ingress만 사용하도록 설정)
serviceAccount:
create: true
name: mimir
annotations:
eks.amazonaws.com/role-arn: ${IAM_ROLE_ARN}
nginx:
enabled: false
minio:
enabled: false
ingress:
enabled: true
ingressClassName: nginx
hosts:
- ${MIMIR_HOST}
mimir:
structuredConfig:
blocks_storage:
backend: s3
s3:
bucket_name: ${S3_BUCKET_NAME}
endpoint: s3.ap-northeast-2.amazonaws.com
insecure: false
tsdb:
dir: /data/tsdb
head_compaction_interval: 15m
wal_replay_concurrency: 3
# Prometheus에서 mimir로 remoteWrite하기
in kube-prometheus-stack
prometheus:
prometheusSpec:
remoteWrite:
- headers:
X-Scope-OrgID: ${원하는_테넌트_이름}
url: https://${MIMIR_HOST}/api/v1/push
여기서 X-Scope-OrgID 는 테넌트 이름이 된다.
해당 헤더별로 그룹핑을 한다고 생각하면 될듯하다.
나는 일단 하나의 미미르에 모든 프롬메트릭을 모으고, 그 안에서 쿵짝쿵짝 하고싶기때문에 모든 프로메테우스의 OrgID를 동일하게 설정했다.
# 고통의 시작 트러블슈팅..🚀
prometheus에서 mimir로 remoteWrite하도록 설정하자,
prometheus와 mimir-distributor 모두에서 아래와 같은 에러 로그가 발생했다.
ts=2024-03-27T23:32:31.590022438Z caller=push.go:171 level=error user=wad msg="push error" err="failed pushing to ingester mimir-ingester-zone-a-0: user=wad: per-user series limit of 150000 exceeded (err-mimir-max-series-per-user). To adjust the related per-tenant limit, configure -ingester.max-global-series-per-user, or contact your service administrator."
어..뭔가 max-global-series-per-user 라는 값의 limit을 늘려줘야 한다는 것 같은데, 도큐나 자료에 친절하게 나와있는게 없어서 애를 좀 먹었다.
온갖 자료들을 다 찾아봤는데, 결국... mimir의 컴포넌트 중 하나인 query-frontend에 접속해 실제 config를 확인하는게 제일 쉬웠다.
참고로 query-frontend는 별도 ingress를 만드는 옵션이 없기 때문에, (물론 path는 설정 가능하지만..암튼) port-forwarding으로 접속해볼 수 있다.

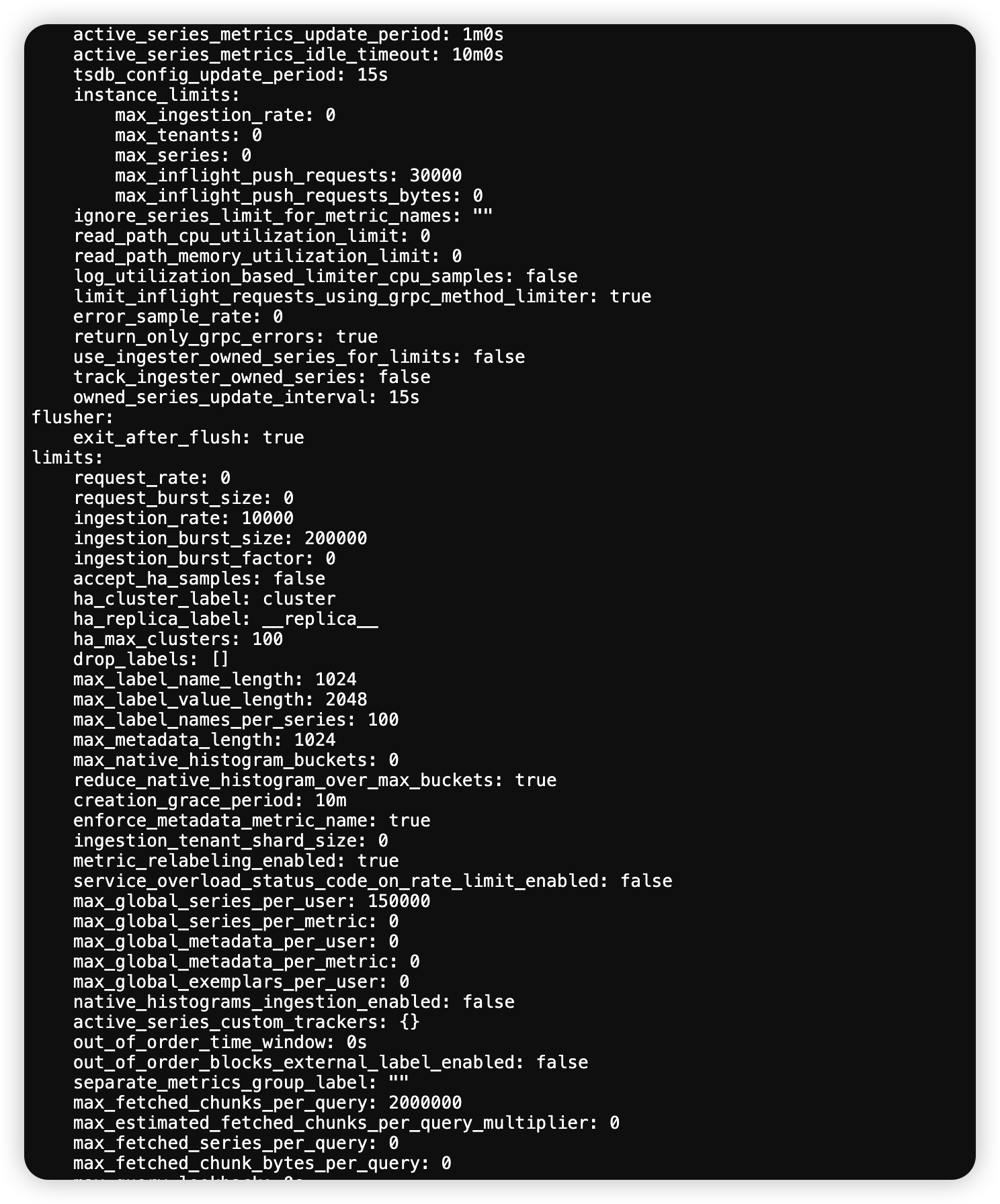
여기서 max_global_series_per_user 라는 값을 검색해보니, 일단 limits 하위 항목이었다.
그런데 overrides_exporter.enabled_metrics 에도 포함되어 있다. <- 이렇게 되면 tenant별 override 항목으로 설정해줘야 한다.
따라서 runtimeConfig.overrides.${원하는_테넌트_이름}.max_global_series_per_user 을 기본값의 10배로 설정해주고 에러는 해소되었다.
runtimeConfig:
overrides:
${원하는_테넌트_이름}:
max_global_series_per_user: 1500000
그러자 다른 에러 로그가 나타났다.ts=2024-03-27T23:45:08.011222343Z caller=push.go:171 level=error user=wad msg="push error" err="the request has been rejected because the tenant exceeded the ingestion rate limit, set to 10000 items/s with a maximum allowed burst of 200000. This limit is applied on the total number of samples, exemplars and metadata received across all distributors (err-mimir-tenant-max-ingestion-rate). To adjust the related per-tenant limits, configure -distributor.ingestion-rate-limit and -distributor.ingestion-burst-size, or contact your service administrator."
→ 이번엔 ingestion_rate & ingestion_burst_size 속성을 손봐줘야겠다.
이 둘은 위와 마찬가지로 limits 하위 항목이지만 tanent별 override 항목이다.
따라서 아래와 같이 override를 또 추가해주고 해소하였다.
runtimeConfig:
overrides:
${원하는_테넌트_이름}:
max_global_series_per_user: 1500000
ingestion_burst_size: 1000000
ingestion_rate: 100000
그러자 또…다른 에러 로그가 나타났다. (이 때 진짜 포기할 뻔 🥲)ts=2024-03-27T23:49:03.011249465Z caller=push.go:171 level=error user=wad msg="push error" err="received a series whose number of labels exceeds the limit (actual: 44, limit: 30) series: 'kube_node_labels{app_kubernetes_io_instance=\"kubecost\", app_kubernetes_io_managed_by=\"Helm\", app_kubernetes_io_name=\"kube-state-metrics\", application=\"kubecost-kube-state-metrics\", helm_sh_chart=\"kube…' (err-mimir-max-label-names-per-series). To adjust the related per-tenant limit, configure -validation.max-label-names-per-series, or contact your service administrator."
제발 마지막이길 빌며, max_label_names_per_series 항목을 찾아보았다.
(그냥 kubecost를 삭제해버릴까도 잠깐 고민했었다... 어디에서 label을 44개나 쓰는지도 못찾았다.)
→ 이 친구도 limits 하위 항목이지만, 테넌트별 오버라이드 항목은 아니다.
따라서 아래와 같이 structuredConfig.limits 에 추가해주었다.
mimir:
structuredConfig:
limits:
max_label_names_per_series: 100
다행히도 마지막 에러로그였고, prometheus 메트릭 데이터들은 mimir에도 쌓이기 시작했다.
# Grafana에서 mimir data source 추가하기
Prometheus Data Source를 클릭한다.
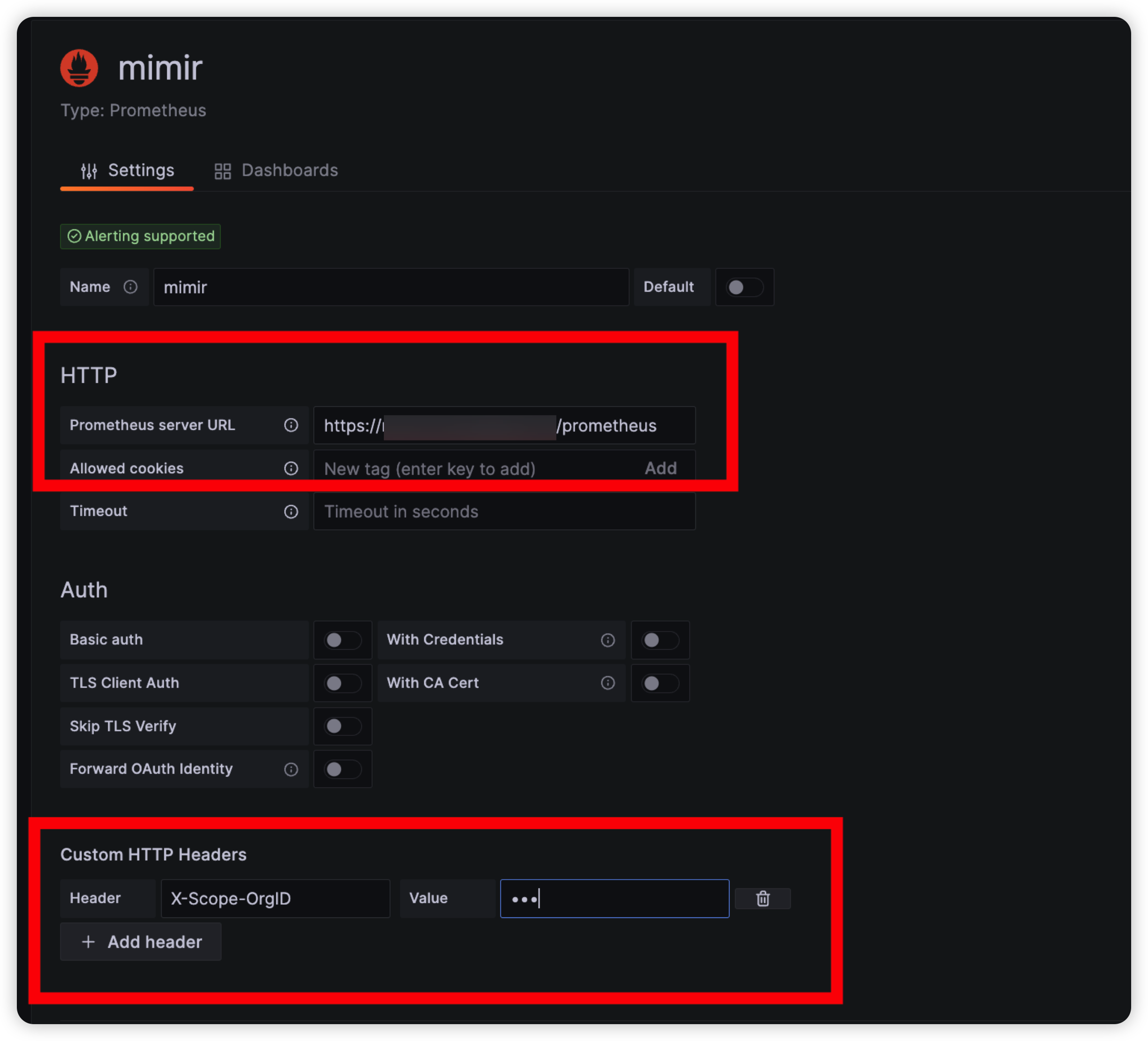
server URL : https://${MIMIR_HOST}/prometheus
custom HTTP Headers: X-Scope-OrgID / ${원하는_테넌트_이름} (prometheus에서 설정한 값)
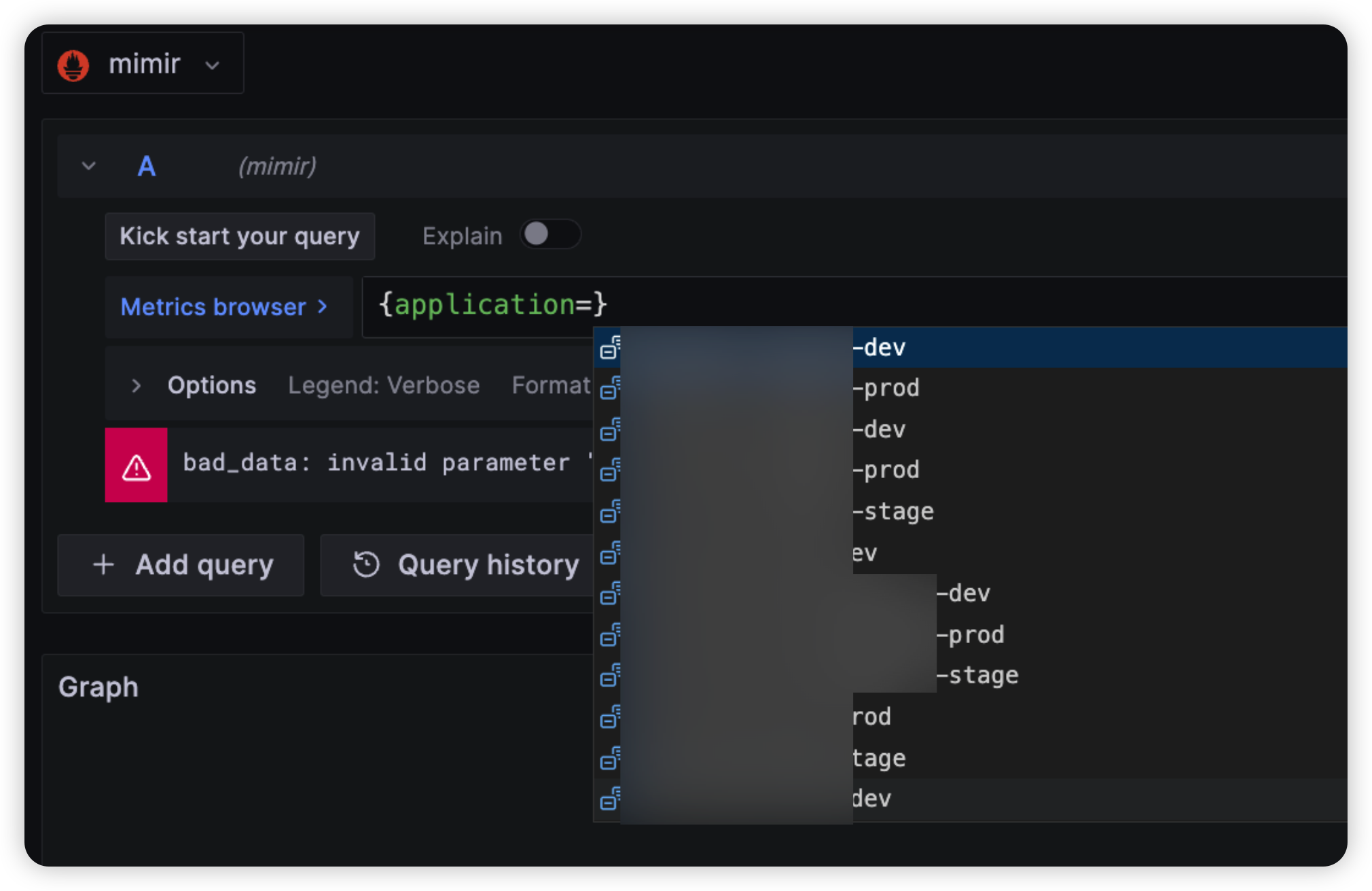
해당 데이터소스 클릭 시, 모든 클러스터의 내용들이 한번에 보이는 것을 확인할 수 있다.
(-dev, -stage, -prod 는 각기 다른 클러스터에 존재하는 애플리케이션들이다.)
# 추가적으로 적용한 사항들
위에서 말했던,,, query-frontend의 admin page들을 확인하기 위해 ingress의 path들을 추가해 주었다.
ingress:
enabled: true
ingressClassName: nginx
hosts:
- ${MIMIR_HOST}
paths:
query-frontend:
- path: /prometheus
- path: /api/v1/status/buildinfo # 여기까지 기본값
- path: /services # Services' status
- path: /config # Including the default values
- path: /config?mode=diff # Only values that differ from the defaults
- path: /runtime_config # Entire runtime config (including overrides)
- path: /runtime_config?mode=diff # Only values that differ from the defaults
ingester의 볼륨 사이즈가 2Gi여서, 50Gi로 늘려주었다.
ingester:
persistentVolume:
enabled: true
size: 50Gi
s3에 저장된 메트릭 데이터들을 평생 볼 필요는 없을 것 같아, 90d 설정을 해주었다.
mimir:
structuredConfig:
limits:
compactor_blocks_retention_period: 90d
# 최종 values.yaml
serviceAccount:
create: true
name: mimir
annotations:
eks.amazonaws.com/role-arn: ${IAM_ROLE_ARN}
nginx:
enabled: false
minio:
enabled: false
ingress:
enabled: true
ingressClassName: nginx
hosts:
- ${MIMIR_HOST}
paths:
query-frontend:
- path: /prometheus
- path: /api/v1/status/buildinfo # 여기까지 기본값
- path: /services # Services' status
- path: /config # Including the default values
- path: /config?mode=diff # Only values that differ from the defaults
- path: /runtime_config # Entire runtime config (including overrides)
- path: /runtime_config?mode=diff # Only values that differ from the defaults
mimir:
structuredConfig:
blocks_storage:
backend: s3
s3:
bucket_name: ${S3_BUCKET_NAME}
endpoint: s3.ap-northeast-2.amazonaws.com
insecure: false
tsdb:
dir: /data/tsdb
head_compaction_interval: 15m
wal_replay_concurrency: 3
limits:
max_label_names_per_series: 100
compactor_blocks_retention_period: 90d
runtimeConfig:
overrides:
${원하는_테넌트_이름}:
max_global_series_per_user: 1500000
ingestion_burst_size: 1000000
ingestion_rate: 100000
ingester:
persistentVolume:
enabled: true
size: 50Gi
mimir 설치 글들을 보면 되게 쉽게 쉽게 하시는데, 난 뭔가 억까(??) 를 좀 많이 당한 기분이다..
저 override 속성 항목들도 내가 다 찾은 후에 정리해두니 쉬워보이는데, 처음에 진짜 찾기 힘들었다.
(mimir 깃헙까지 까봄)
나처럼 고생하는 사람이 한 명이라도 줄길 바라며...
끝!!
'공부 > Monitoring' 카테고리의 다른 글
| grafana api콜버튼 플러그인 (in helm chart) (1) | 2024.08.28 |
|---|---|
| [Robusta] 직관적인 쿠버네티스 클러스터 알람 받기 (8) | 2024.06.06 |
| [grafana] provisioned Datasource/ContactPoint 제거 (0) | 2023.09.05 |
| [Grafana Loki] Errors loading rules (2) | 2023.07.27 |
| [DataDog] Ingested/Indexed Log + Archiving 정리 (0) | 2022.05.14 |






댓글