





728x90
728x90
한 줄 후기 : 당근은 개발자 경험(DX)에 진심이다. (부럽,,)
- 제일 놀랐던 점 : SRE팀이 16명이다 (전체 엔지니어는 200명 넘는 듯) (플랫폼?파트, 클라우드 파트, 클러스터 파트)
- 내가 나중에 만들고 싶다고 생각한 플랫폼 다 만들어져 있음
- 나도 나중에 꼭 만들어야지......
아래는 밋업 당시 그 자리에서 바로 정리하며 적은 내용들이며, 정리가 덜 되어있을 수 있습니다.
1️⃣ 당근마켓 개발자 플랫폼: 지난 2년간 무엇을 만들었는가? (변정훈)
https://blog.outsider.ne.kr/ <- 블로그 주인 분
- 당근마켓 개발자 플랫폼 - Kontrol
- 서비스 개발 -티켓 요청-> SRE (전체 인프라 관리) -작업(자동화: 스크립트, IaC)-> 인프라
- 입장 차이
- 서비스 개발 - 빠른 변경, 다양한 시도
- SRE - 안정적 운영, 정책 적용, 일관된 형태, 승인
- 양쪽 모두 불편하다.
- 커가는 조직과 서비스 규모 - 200명 넘는 엔지니어, 4개 리전, 8개 클러스터 (서비스만), 200 이상 네임스페이스 (프로젝트별로 네임스페이스를 갖는다)
- 엔지니어 → 플랫폼 을 제공 (Developer self-service)
- 디자인 원칙 : Low Threshhold, High Ceiling, and Wide Walls
Kontrol : SRE 팀에서 제공하는 프로젝트 컨트롤 플레인 (21년 7월 사내 오픈)
- 프로젝트 등록 > 배포, 쿠버 리소스 가시화까지 (깃헙과 흡사한 UI)
- Deployments, Workloads (k8s), CronJobs, Resources, Cost, Settings
- 헬름 템플릿도 보여줌
- 역할 정책 검사기
- 쿠버 리소스는 알고시디보다는 조금 더 추상화해서 필요한것만 보여주며, 알고시디 기능 모두 제공
사내 개발자 → Kontrol → GoCD → k8s
+ 사내 개발자 → Kontrol → k8s
→ 사내 개발자 → Kontrol → argoCD → k8s
오너십 : Katalog란 서비스 띄워서 서비스별 오너십 관리, AWS 리소스도 같이 관리
Kontrol → DB, argoCD, Katalog
비용 : kost
마찬가지로 Kontrol에서 확인 / SP의 할인율같은건 고려 제외
→ 실제 정확한 비용 체크보단 각 팀별 예산 확인 및 승인, 비용 시각화
리소스 생성 : krp
개발자가 리소스 생성도 바로 가능 (redis 등)
이 모든 서비스들을 Kontrol이란 단일 UI로 제공
Developer Experience 매우 중시 (개발자 사용자 경험)
플랫폼으로 얻은 이득
- 인프라 작업 요청 감소
- 설정 디버깅 시간 감소
- 설정 변경 시 일괄 적용
- 통일된 인프라
사내 플랫폼
- 경쟁 제품이 없음
- 제공자의 입장에 빠지기 쉬움
- 내부에 있는 고객
- 범용성보다는 조직에 최적화
2️⃣ 당근마켓 개발자 플랫폼: 전사 배포 시스템을 만들기 전 알았으면 좋았을 것들 (김규환)
2년동안 내부 전사 배포 시스템을 만들었던 경험과 인사이트를 공유
1. 배포 시스템 특징 및 현황
- Kontrol 주요 특징
- Container 애플리케이션
- Dockerfile과 jib(JVM) 빌드 지원
- Low Threshold
- Self Service
- Kontrol 배포 현황
- 1분기 기준 약 5700건 배포 (Kontrol 통한것만), 일 평균 76건
2. 개발자와 SRE간 이해 관계
- 개발팀 != SRE팀 관점
- 개발팀
- 빠르게 배포하고 싶다
- 문제가 있을 때 빠르게 롤백하고 싶음
- 애플리케이션 문제를 빠르게 파악하고 싶음
- SRE
- 안정적으로 운영
- 파편화된 구성들을 일괄적으로 관리
- Low Threshold 제공
- Kontrol Concept 과 개발팀 고유 문화 간 충돌
- 예시 1
- 컨트롤 컨셉 : 이미지는 각 환경 구분 없이 한 번만 빌드
- 개발팀 고유 상황 : 환경별로 각 이미지들을 빌드해야 하는 앱을 개발하는 개발팀
- 예시 2 (ex, 광고팀)
- 컨트롤 컨셉 : 모든 프로덕션 배포는 알파 환경을 거쳐서 배포
- 개발팀 고유 문화 : 프로덕션 환경에 바로 배포하는 케이스가 있는 개발팀
- 예시 1
- SRE팀에 대한 신뢰가 저하되면 아무도 원치 않고, 아무도 사용하지 않는 시스템이 된다.
- 공동 목표를 지원하기 위한 시스템 → 공통 인센티브 만들어야 함
- 어떻게? 포장 도로와 비포장 도로 비유
- 포장도로 - 일반적으로 목적지에 더 쉽게 도달 가능, 인지부하가 낮은 설정, 내부 인프라 친화적 구성
- 비포장도로 - 상대적으로 개발팀의 역량에 따라 목적지에 이르는 속도가 달라짐
- SRE팀은 분명 포장도로를 만들어서 개발팀을 편하게 해주려고 하는 것이다. 개발팀이 이를 잘 알 수 있도록 설득 또는 홍보를 잘 해야 함 (또는 원하는 기능들을 많이 만들어줌)
- 주요 운영 지표 활용 → 좀 더 일찍부터 쌓지 못한것에 대한 아쉬움
- 기간 별 배포 수
- 배포 별 배포 소요 시간
- 배포 실패율
3. 운영 컨텍스트 제공
- 기존 argoCD 한계 - Config & Secret 변경 이력 확인에 대한 어려움
- 사용자 이벤트를 이용해 컨텍스트 전달
4. 요약
- 포장도로와 비포장도로 개념으로 운용
- 핵심 지표들을 최대한 빠르게 준비
- 의미있는 컨텍스트들을 적절한 곳에서 제공
3️⃣ 당근마켓 개발자 플랫폼: 클릭! 클릭! 글로벌로 향하는 멀티 클러스터 지원 스토리 (유병화)
- 당근마켓의 서비스 배포 시스템 (22년 6월)
- ArgoCD
- k8s 잘 알아야 함
- jira로 요청, 사람이 처리
- 중앙 통제가 쉽지 않고 설정 파편화 문제
- 자유도 높고, 여러 글로벌 리전 배포 가능
- Kontrol
- 낮은 진입 장벽
- 셀프 서비스
- 중앙 통제, 표준화 쉬움
- 자유도가 높지 않고, 한국 리전만 배포 가능
- ArgoCD
- 딜리버리 파트 2022년 2분기 OKR > 23년 1분기 OKR까지 글로벌 배포 지원
- 구조 설계
- 서비스를 배포할 리전 목록 설정을 어떻게 관리할지?
- A/프로젝트 저장소의 values.yaml file
- B/ Kontrol DB > 채택
- prod 배포 승인을 리전별로 할지? ㅇㅇ (잘못된 버전을 모든 리전에 배포하게 될까봐)
- stateless 파이프라인 도입 (GoCD 파이프라인)
- 서비스를 배포할 리전 목록 설정을 어떻게 관리할지?
- 개발 경험을 높여주었던 3대장
- 1. TypeScript
- 2. Prisma, auto DB schema migration
- 3. Graphite (높은 퀄리티 코드 리뷰 해줄 수 있게 도와줌)
- 글로벌 오픈 일정이 약간 늦어지더라도 argo workflow를 도입해서 같이 글로벌 작업 진행한다
4️⃣ 당근마켓 개발자 플랫폼: 프로젝트 오너십 관리를 통한 DevOps 기반 만들기 (김효민)
- 클라우드 리소스 오너십 관리의 필요성
- AWS, GCP … 수많은 리소스들이 다양한 목적을 가지고 생성되고 있다.
- AWS 태그와 GCP 라벨 로 관리
- 클라우드 파트의 고민
- 1. 하나의 팀 (클라우드 파트)이 모든 리소스 오너십 정보를 추적 / 관리하기 힘들다
- 2. 오너십 정보에 대한 신뢰성이 떨어진다.
- 채팅A팀이 플랫폼 부문에서 사라졌는데, 이 리소스는 어느 팀 리소스라고 생각해야 하는가?
- 플랫폼의 다른 팀으로 오너십 이전? 다른 부문의 채팅팀으로 오너십 이전?
- 결론 : 기존 채팅A팀 멤버에게 물어봄 > 일단 바쁘니까 나중에 얘기하자 > 장애나면,,? ㅠㅠ
- 플랫폼에서 오너십이 없을 경우
- 특정 프로젝트의 담당자를 찾기 어렵기 때문에, 장애가 발생했을 때 빠르게 대응하기 어렵다
- 프로젝트가 사용하고 있는 클라우드 리소스를 확인 및 관리하기 어렵다
- 신뢰성 있는 오너십 정보를 한 곳에서 통합 관리하자!
- 프로젝트에 오너십을 제공하고, 오너십 기반으로 여러 메타데이터 관리하는 서비스 만들면 인사이트 제공할 수 있는 데봅스 기반 만들 수 있을 것.
- → Katalog (karrot + service catalog)
- Katalog
- katalog의 전신 : 스프레드시트 (ㅋㅋ) 잘 쓰고 있긴 했다.
- katalog 프로젝트 생성 > k8s cluster 내에서 각각의 서비스가 namespace로 구분
- 팀 태그 - 회사에서 관리하는 HR API에서 따오기 때문에 팀 이름이 바뀌거나 해도 문제 없다
- Golang 사용. 이유 : 사내에서 Go를 많이 쓰고 있어서 배워보려고 시작함
- AWS Tag Editor API 활용
- GCP Cloud Asset API > 이건 Label Update기능이 없고, 한번에 불러올 수 있는 api 한계도 있어서 그냥 각 서비스별 라벨 api 병렬적으로 실행
- katalog 미래
- 1. katalog의 확장
- Kontrol의 katalog
- Datadog의 Service Catalog
- 2. katalog를 활용하는 서비스들의 확장
- 오너십 기반으로 알림 서비스
- 오너십 기반 비용 대시보드
- 오너십 기반 클라우드 리소스 self 운영 서비스
- …. 등등
- 1. katalog의 확장
5️⃣ 당근마켓 개발자 플랫폼: (쉽고 빠르고 안전하게) 개발자가 직접 관리하는 클라우드 리소스 (김승호)
44bits 운영진
- 인프라 리소스 관리 : IDC(손, 창업 시점) > ansible, puppet, chef .. (코드, 개발팀이 늘어남) > Cloud 등장 (손, 인프라팀 구성) > Terraform (코드, 인프라팀이 늘어남)
- 기존 현황
- 개발팀이 직접 리소스 생성 관리 가능 (테라폼 코드 pr or 콘솔 조작 가능)
- 모든 개발팀에 테라폼 개발자가 존재할 수 없다는 현실도 인정
- 테라폼 운영이 부담되기 시작
- 1000개 정도 테라폼 state
- 3년 전에 만들고 한 번도 수정하지 않은 프로젝트에 리소스 추가하려면?
- 테라폼 버전, 프로바이더 버전, state 맞추다가 하루 금방…
- 특정 리소스만 apply 또는 수동 작업 > 이럴거면 테라폼 왜쓰냐
- 해결책
- 개발팀마다 클라우드 계정 주고 인프라 관리 일임
- 개발팀 인력 부담, 인프라 비효율
- 개발팀의 모든 권한을 뺏어서 인프라팀이 관리
- 인프라팀 인력 부담, 개발팀 효율 저하
- 당근마켓 개발문화와 어울리지 않음
- 개발팀마다 클라우드 계정 주고 인프라 관리 일임
- 테라폼만큼 어렵지 않고, 인프라팀 안기다리고, 내부 관리 규칙 준수하면서 개발자가 직접 인프라 만들고 관리할 수 없을까? > KRP (karrot resource platform)
- 빨리 하려고 파이썬/fast api 사용
- db 도입은 최대한 늦추겠다. 처음부터 필요했다면 장고 선택했을 듯
- AWS - boto3 (테라폼과 헤어질 결심)
- KRP의 목표 : 누구나 당근마켓 표준 설정이 적용된 AWS 리소스를 고통 없이 직접 만들어 사용할 수 있다.
- key result : 반복되는 aws 리소스 생성 Jira 리슈 개수 0개
- 리소스 구현 우선순위 정하기 - 요청받은 Jira ticket 기준, redis부터 시작
- UI 뒤편에서는 당근마켓 규칙 적용
- redis별 서브넷 그룹 생성
- 계정, 환경별 값 지정 - subnet, security group, az, snapshot window, maintenance window
- 태그 설정, 엔진 버전별 파라미터 그룹 지정
- 데독 대시보드 & 슬랙 메세지까지
- redis 구현 순서
- 생성, 상세 API 구현
- 생성 상세 ui 구현 & 수정 기능 API 구현
- 이슈 템플릿에서 안내 & 수정 UI 구현
- redis 대한 개발자의 클라우드 권한을 삭제
- 회고
- DB도입은 늦추길 잘했다. > 처음에 DB가 없어서 빠르게 기능 개발에 집중 가능했음 / 10개월쯤 지난 지금 도입 필요해져서 하는중 : FastAPI + SQLAlchemy 사용
- Boto3 API가 생각보다 복잡하다
- 지나치게 쪼개진 API Client들
- 내부적으로 비동기처리여서 응답은 빠르지만 그래서 번거롭기도
- 생성 도중 실패하면 중간에 생성했던 리소스도 삭제 필요
- 그러나 대안 없음
- 만족
- SRE 개입 없이 규칙에 맞는 리소스 생성 및 사용 가능
- 추가 대응 중인 리소스 - StaticSite (S3 + CloudFront + Route53) / DynamoDB
6️⃣ 당근마켓 서비스를 모니터링하는 방법 (배상익)
SRE 클러스터파트 리드
- 당근마켓의 과거와 현재
- 1년 반 전 1회 밋업
- 조직구조와 scalability 에 대한 고민 > 정책을 잡는 것 부터! (지반이 탄탄해야 한다)
- 인프라 정책 다듬기
- 기술 부채와 파편화, 비용 대해 항상 경계
- 메타데이터를 정의하고 효율화하는 부분에서 정책은 굉장히 중요
- superset
- 모니터링 방법론
- USE method - Brendan gregg
- Utilization
- Saturation
- Errors
- RED method - Tom wilkie (google출신, use method는 레거시다)
- Rate
- Errors
- Duration
- Four golden Signals - Google SRE book
- USE method - Brendan gregg
- 당근마켓 모니터링 방법
- 당근마켓 모니터링 인프라 : 프로메테우스, cortex, loki 등 > 그라파나
- Sub로 데이터독 고움 받는 중 (APM, Cloud Integartion), Watchdog도 slack 연동해서 쓴다
- 비용땜에 로그는 데독으로 안보내고, APM만 잘 씀
- 모니터링 방법론을 우리 상황에 맞게 구현
- 서비스 대시보드
- 네임스페이스 기준으로 자신의 서비스를 더 잘 이해할 수 있도록
- 일관성 있는 대시보드
- 서비스 overall 대시보드 : 전역적으로 모니터링하며 alert-delivery 와 연계
- 서비스 대시보드
- 변화하는 상황에 따른 대시보드 축적
- 장애일지와 대시보드 보강
- 장애일지에 5 whys와 lesson learn 작성
- 1분기 OKR 비용절감
- Container CPU limit 해제에 따른 노드 모니터링 보강 - CPU, Memory, Disk, Network, …etc
- Spot instance 프로덕션 도입에 따른 Pod Eviction 리스트 및 대시보드 보강
- Locality Load Balancing 적용
- 장애일지와 대시보드 보강
- 인프라 닥터 대시보드 구축중
- Istio Doctor Dashboard
- HAProxy Doctor Dashboard
- Kube-System Doctor Dashboard
- Infra Planning
- 메트릭, 대시보드 등의 도움을 받아 capacity planning에도 사용
- 영향도를 고려해 작업 우선순위 결정
- 역량 축적 (인프라실 비전)
- 지식공유의 휠을 대시보드와 얼럿시스템 보강으로 더 돌리기
- 당근마켓 서비스의 안정성과 SRE 역량 강화로 이어지고
- 이를 토대로 예측 가능한 인프라를 만든다고 믿는다.
7️⃣ Amazon EKS 데이터 전송 비용 절감 사례 (허진수)
Multi-AZ EKS 클러스터에서 Locality LB를 활용한 비용 절감 사례 (EKS: Cross Zone traffic 절감, Istio)
- Visibility
- 어떤 pod들이 cross-zone traffic을 많이 발생시킬까?
- VPC Flowlog & Pod Metadata 결합해서 Cross-Zone Traffic 확인
- 어떤 pod들이 cross-zone traffic을 많이 발생시킬까?
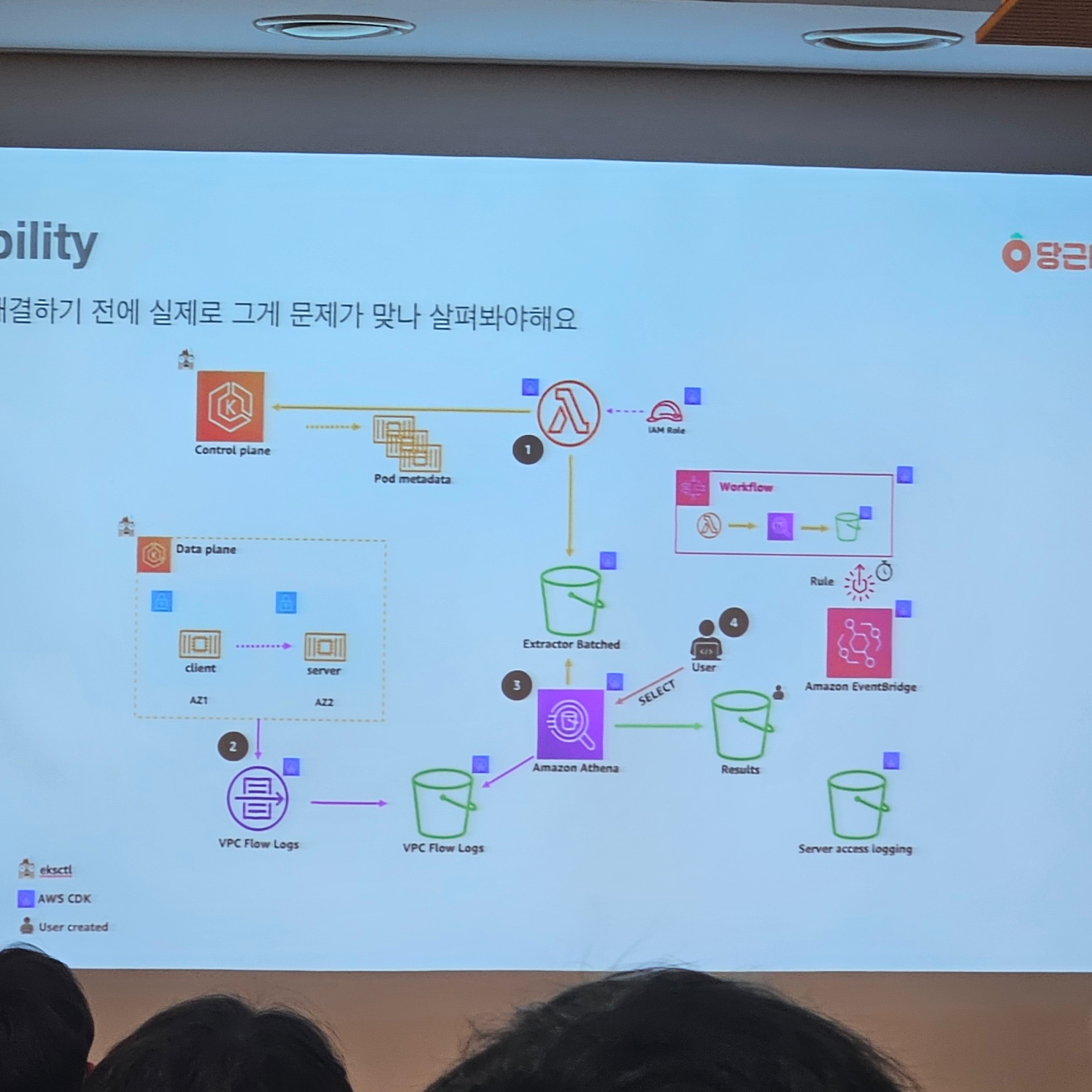
- istio ingress gateway가 주범!
- istio mesh 안에서도 많이 발생
- istiod가 비용 진짜 많이 먹고… monitoring도 많이 먹음
- Istio Locality LB
- EKS Worker Node 정보엔 Topology 정보가 있다.
- Istio는 이 정보를 긁어와서 Proxy Config 에 담는다
- 정보를 알고 있으니, 같은 존에 있는 pod로 트래픽을 보내는 것이 가능할 것이다!!
- Locality LB가 잘 적용되면 같은 존의 pod로만 트래픽을 보내야 함
- 적용하는 법 - meshConfig에 LLB Setting enable: true 옵션이 있음
- Istio OutlierDetection
- failover를 위해 필요함
- 같은 존에 파드가 없거나 불능 상태일때 다른 존으로라도 보내야 함
- Topology Aware Hintes
- Cost : 바로 다음날 비용이 절반으로 줄어듦 - 지금은 거의 7만불 정도 줌(한달에)
- 가용성과 부하 분산에 대한 고민
- AZ가 무너지면 자동으로 Failover
- 진짜 문제는 균등 배포가 깨졌을 때
- 모든 pod가 균등하게 트래픽 분산 X
- 싱글존 EKS의 active-active 구성
- How it works? (istio LLB)
- Istio
- 서비스 메시를 구현하는 오픈소스 프레임워크
- 마이크로서비스 간의 통신을 제어하고 관리할 수 있는 기능 제공
- Istio LLB 동작
- 1. 클라이언트가 서비스에 요청
- 2. 요청은 클라의 envoy 프록시 통해 전송
- 3. envoy 프록시는 llb 설정에 따라 다음과 같은 순서로 백엔드 선택
- ,,,
- Istio
8️⃣ grafana를 활용한 프로젝트별 알림 구축 (이시은)
- grafana alert 소개
- Alerting : legacy … grafana v10부터 지원 X → 업그레이드 후 alert system 전부 마이그레이션할 예정
- Rule
- Evaluate Every : 몇 분에 한 번씩 평가한다
- Evaluate for : 몇 분 동안 지켜본다
- Conditions
- 알림 평가 조건
- grafana alert의 한계
- 평가된 모든 time series가 하나의 메세지로 전송
- 네임스페이스별 알림 대응 불가능
- 메세지 내용 커스텀의 한계로 인한 가독성 저하
- 알림 종류별 reminder 시간 조정 불가능
- 프러젝트뱔 담당자 정보를 함께 보고 싶은 니즈
- Alert Delivery의 등장 w. katalog
- 알림을 namespace별로 나눠서 한 메세지엔 한 네임스페이스에 대한 알림만 오게 하자
- 가독성 높이자
- 개별적 알림 제어
- 알림에 담당자 정보 표시
- 전체 알림 상황 볼 수 있는 web ui까지
- Alert Delivery의 효용
- 개발자들의 self-service 가능
- 이슈 진행상황에 대해 SRE와 공유
- 개별 알림 제어로 verbose한 알림 줄어듬
- 매 시간마다 알림 진행상황 리포트
- WEB UI : namespace별 history 쉽게 확인하고, 전체 알림 현황 시각화
- 과제
- 알림 별 시간/조건 정책을 구체화하여 알림과 멘션 하나하나의 중요도 높이기
- 그라파나 쿼리 튜닝
- 변화하는 인프라 상황에 유연하게 대처
- 알림 관련 report 고도화
QnA
- 클러스터 업그레이드는 유튜브 유정열님 발표 보면 좋을거다 (앞단 프록시)
- SRE팀 총 16명
- 자료는 유튜브에 올라가며 그 때 발표자료도 올라간다
- Kontrol은 알고시디로 배포 > 그래도 조회는 Kontrol로 할 수 있음
728x90
728x90
'공부 > 기타' 카테고리의 다른 글
| [PostgreSQL] Docker로 뜬 PostgreSQL DB -> RDS data 마이그레이션 (0) | 2023.09.15 |
|---|---|
| [대규모 시스템 설계 기초] 5장 - 안정 해시 (Consistent Hash) 설계 (0) | 2023.06.17 |
| [Sonarqube] Community Edition & PR decorate Plugin docker-compose (0) | 2023.05.17 |
| [NHN Cloud] VPC부터 Instance 접속까지 (AWS와 비교) (1) | 2023.03.11 |
| [DNS] TXT 레코드와 SPF, DMARC (0) | 2022.05.13 |






댓글